-
[Week 7] Support Vector MachineCourses/Andrew Ng - Machine Learning 2022. 1. 23. 16:12
Optimization Objective
이번 시간에는 Support Vector Machine 알고리즘에 대해 배워보겠습니다. 서포트 벡터 머신은 복잡한 비선형 함수를 학습하는 점에 있어서 더 간단하고 강력한 알고리즘입니다.

로지스틱 회귀와 비교해 보겠습니다. 로지스틱 회귀의 -log(sigmoid) 함수 그래프를 표시해봅니다. 분홍색으로 새로운 그래프를 그렸습니다. y=1일 때 z가 1 이하이면 근사치 직선을 그립니다. z가 1 이상이면 0입니다. 반대로 y=0일 때 z가 -1 이상이면 근사치 직선을 그리고 -1 이하면 0의 값을 갖습니다. 이것이 SVM의 비용 함수 그래프입니다. 새로운 함수를 Cost1(z), Cost2(z) 로 부릅니다.

역시 로지스틱 회귀에서 아이디어를 확장해나갑니다. log 항을 방금 정의한 cost함수로 대체합니다. 1/m 항도 제거합니다. 1/m 항을 제거해도 최적값을 찾는데는 문제가 없습니다. 그리고 정규화 항의 람다를 빼고 C라는 새로운 파라미터를 사용합니다. C는 1/lambda 같은 역할입니다. 즉 , C가 커질 수록 정규화 항의 영향력은 낮아집니다.
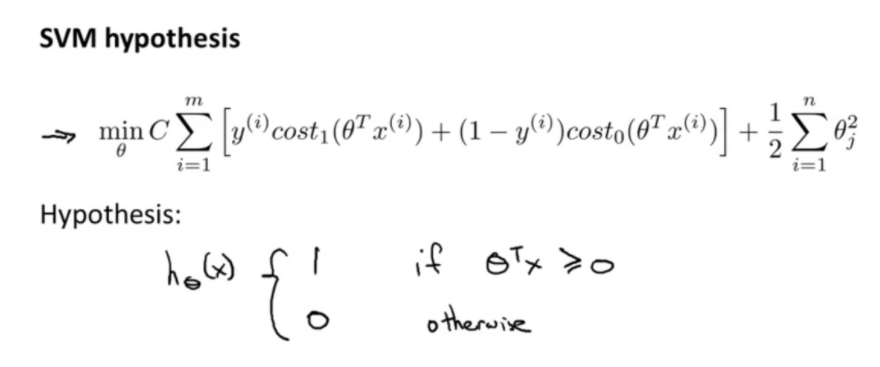
이제 이 비용 함수를 최적화하여 파라미터를 얻습니다. 서포트 벡터 머신은 로지스틱 회귀와는 다르게 확률을 출력하지 않습니다. 그 대신 이 가설 함수가 y=1인지 y=0인지 예측값을 출력합니다.
Large Margin Intuition
서포트 벡터 머신은 큰 마진 분류기라고도 불립니다. SVM 가설에 대해 좀 더 알아봅니다.

로지스틱 회귀에서 z의 결과값이 0 이상이면 y=1일 확률이 높고 0보다 작다면 y=0일 확률이 높아집니다. 그렇지만 0.1과 -0.1의 차이는 크지 않지만 결과값은 확연히 1과 0으로 달라집니다. 서포트 벡터 머신은 이렇게 애매하게 분류하지 않고 0보다 훨씬 더 커야만 1로 분류하고, 0보다 훨씬 작아야만 0으로 분류합니다. cost1함수를 보면 z가 1이상이어야만 오차가 0으로 확실하게 y=1로 분류합니다. cost0의 경우 반대입니다. 따라서 서포트 벡터 머신은 안전 마진을 갖게 됩니다.
C값이 매우 크다고 상상해봅시다. 서포트 벡터 머신은 첫번째 항을 0에 가까운 값으로 설정할 것입니다. 첫번째 항을 0으로 만들기 위해서는 y=1일 때 z는 1보다 커야 하고 , y=0이면 z는 -1보다 작아야만 합니다.

위와 같은 데이터 셋이 주어졌을 때, 분홍색 선이나, 녹색 선이나 둘 다 결정 경계가 될 수 있습니다. 그렇지만 둘 다 좋은 선택같지는 않습니다. 서포트 벡터 머신은 검은색 선을 결정 경계로 정합니다. 검은색 선은 파란선을 마진으로 갖습니다. 서포트 벡터 머신은 마진이 크도록 데이터를 분리합니다.

C가 적당한 값이라면 검은색 결정 경계에서 튀는 값이 있더라도 분홍색 선으로 수정되지 않습니다. 서포트 벡터 머신은C가 적합한 값이고 튀는 데이터 소수를 무시할 때 더 좋은 결과를 보여줍니다.
혼자서 강의를 듣고 정리한 것이니 틀린 점이 있다면 언제든지 지적 부탁드립니다 :)
'Courses > Andrew Ng - Machine Learning' 카테고리의 다른 글
[Week 7] SVMs in Practice (0) 2022.01.23 [Week 7] Kernels (0) 2022.01.23 [Week 6] Machine Learning System Design (0) 2022.01.18 [Week 6] Bias vs. Variance (0) 2022.01.16 [Week 6] Evaluating a Learning Algorithm (0) 2022.01.14